

我中心在AI4Science领域取得突破,研究成果入选《Chemical Science》封面论文
近期,我中心主任吕建成教授课题组与四川大学华西医院柯博文教授课题组展开深度合作,在人工智能驱动的药物发现领域取得重要突破。相关研究成果以封面论文的形式发表于英国皇家化学会(Royal Society of Chemistry, RSC)旗舰期刊《Chemical Science》。该期刊作为RSC旗下的综合性化学顶刊,旨在报道化学各前沿领域的突破性研究。

图1 《Chemical Science》期刊第17(10)卷封面
研究成果以“Few-shot molecular property optimization via a domain-specialized large language model”为题发表。四川大学计算机学院(软件学院、智能科学与技术学院)为该论文第一完成单位,合作单位为华西医院。四川大学计算机学院2023级硕士研究生郭彦为第一作者,四川大学医学前沿科学中心2023级博士研究生罗梦兰为共同第一作者,由我中心主任吕建成教授课题组的刘祥根副教授与柯博文教授担任通讯作者。该研究提出了一种专门为分子优化定制的大语言模型DrugLLM,显著提升了在小样本条件下的药物发现效率。
论文概要:在药物研发中,从有限数据中学习分子结构与药理活性之间的复杂关系(Structure-Activity Relationships, SAR)是核心挑战。现有的大语言模型在处理化学领域时,由于无法捕捉分子结构的细微特征,其应用受到严重限制。基于此,本文提出了DrugLLM。该模型引入了官能团分词策略(Functional Group Tokenization, FGT),将分子表示为具有语义信息的化学子单元,相比传统的SMILES编码实现了53.27%的序列压缩。此外,研究团队提出了一种“下一修改预测”(Next Modification Prediction, NMP)范式,通过模仿资深药物化学家的迭代推理过程,使模型能够基于极少量(<10个)示例,自动学习如何通过修改分子结构来优化特定药理属性。
创新点:
- 提出NMP训练框架,将药物分子优化过程建模为连续结构修改序列,使模型能够模拟药物化学家逐步改造分子的思路。
- 提出功能基团级别的分子表示方法FGT,将复杂分子结构分解为具有化学意义的结构单元,相比传统SMILES表示可减少约53%的序列长度,并提高模型对分子结构的理解能力。
- DrugLLM能够在仅提供少量优化示例的情况下生成具有更优性质的新分子,实现类似人类专家的推理式分子设计能力。
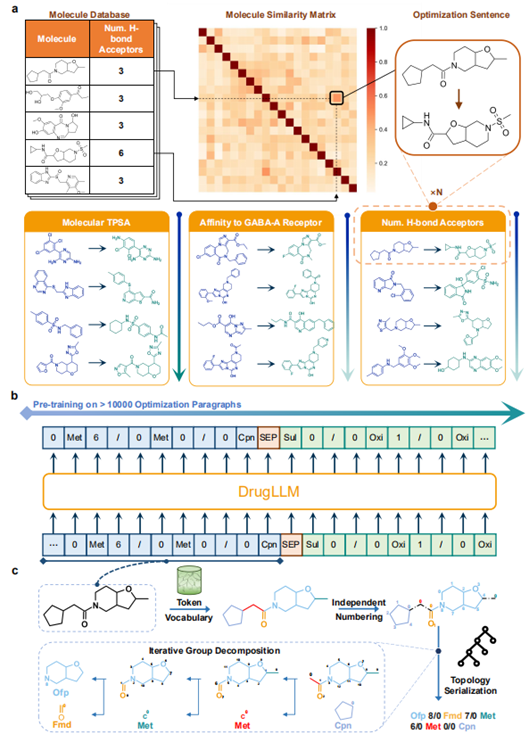
图2DrugLLM框架的原理概览
实验结论:实验结果表明,DrugLLM在分子优化任务中展现出显著优势,仅需8个示例即可实现与基于3.4万分子训练的图神经网络模型相当的优化效果。研究团队设计了24项分子优化任务进行评估,包括4项理化性质优化任务和20项针对不同生物靶点的活性优化任务。结果显示,在少样本条件下,DrugLLM的优化成功率显著优于现有分子生成模型,并在所有任务中取得最佳表现。进一步的生物实验验证显示,利用DrugLLM设计的HCN2抑制剂候选分子在膜片钳实验中抑制活性优于已上市药物伊伐布雷定,证明了该方法在实际药物分子优化中的潜在应用价值。
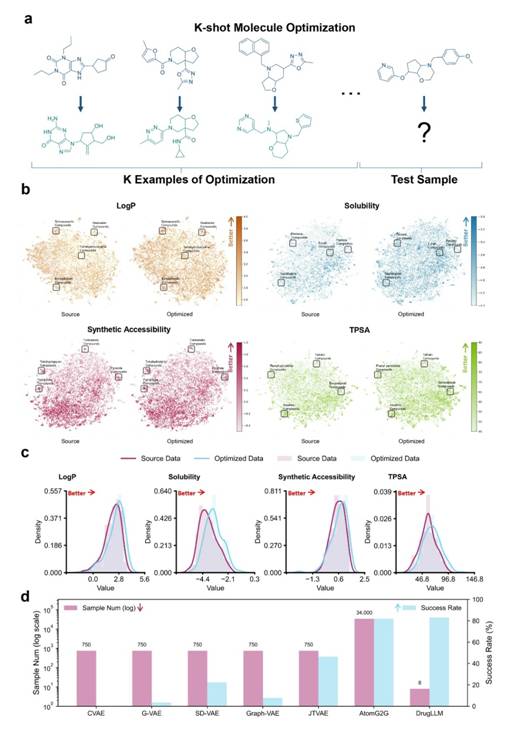
图3少样本分子优化中分布情况的比较
论文地址:https://pubs.rsc.org/en/content/articlelanding/2026/sc/d5sc08859c
代码地址:https://github.com/ziyanglichuan/DrugLLM
部分作者简介:

郭彦,四川大学计算机学院2023级硕士研究生。研究方向为自然语言处理。

罗梦兰,四川大学医学前沿科学中心2023级博士研究生。研究方向为麻醉镇痛新药研究。

柯博文,四川大学教授,博士生导师,华西医院/临床医学院副院长。研究方向为临床导向的麻醉新药创制。

刘祥根,四川大学副教授,博士生导师。研究方向包括文本生成、模式识别、AI药物设计。