

我中心在扩散模型、CAD自动设计及多模态检索等领域取得重大突破,相关成果被ACM MM接收
近日,我中心3篇论文被2025 ACM国际多媒体大会(ACM International Conference on Multimedia,ACM MM)接收。ACM MM是多媒体及多模态领域的国际重要会议,也是中国计算机学会收录的计算机图形学与多媒体领域A类(CCF-A)会议。ACM MM 2025将于2025年10月27日至10月31日在爱尔兰首都都柏林召开。
论文1:Enhancing Diffusion Model Stability for Image Restoration via Gradient Management
1. 研究背景
基于扩散模型的AI图像修复技术,如图像去模糊、超分辨率和图像补全,已成为计算机视觉领域的研究热点。现有主流方法通常采用贝叶斯框架,通过结合预训练扩散模型的“先验知识”(Prior)和观测数据的“似然引导”(Likelihood Guidance)来恢复高质量图像。
然而,这些方法在迭代过程中简单地将两个部分的更新梯度相加,忽视了它们之间潜在的相互作用。这种“盲目”结合会严重影响模型的收敛效率和最终的图像修复质量,导致生成图像中出现伪影、模糊和细节丢失等现象。
2. 本文方法:稳定逐进梯度扩散(SPGD)
针对上述挑战,本文提出了稳定逐进梯度扩散(Stabilized Progressive Gradient Diffusion, SPGD)算法。该方法的核心思想是对梯度进行精细化管理,通过引入两个协同工作的创新组件,从根源上解决梯度冲突与波动问题:(1)逐进似然预热:为解决“梯度冲突”,在每一步正式去噪前,SPGD引入了一个“预热”阶段。它会先进行多次小步长的似然引导更新,让图像估计值“逐步地”适应观测数据,从而有效缓解了后续去噪步骤中的方向冲突;(2)自适应方向动量平滑:为解决“梯度波动”,SPGD采用了一种新颖的自适应动量平滑技术。它不仅会像传统动量法一样参考历史梯度信息,还会根据当前梯度与历史梯度的方向一致性,动态调整动量的“信任度”。当方向稳定时,它充分利用历史信息进行平滑;当方向突变时,它会降低对历史信息的依赖,从而有效抑制了梯度的剧烈波动,确保更新方向更加稳定可靠。
3. 实验结果
本文在FFHQ人脸数据集和ImageNet通用数据集上,针对图像补全、高斯去模糊、运动去模糊和超分辨率等多种修复任务进行了全面的定量与定性评估。
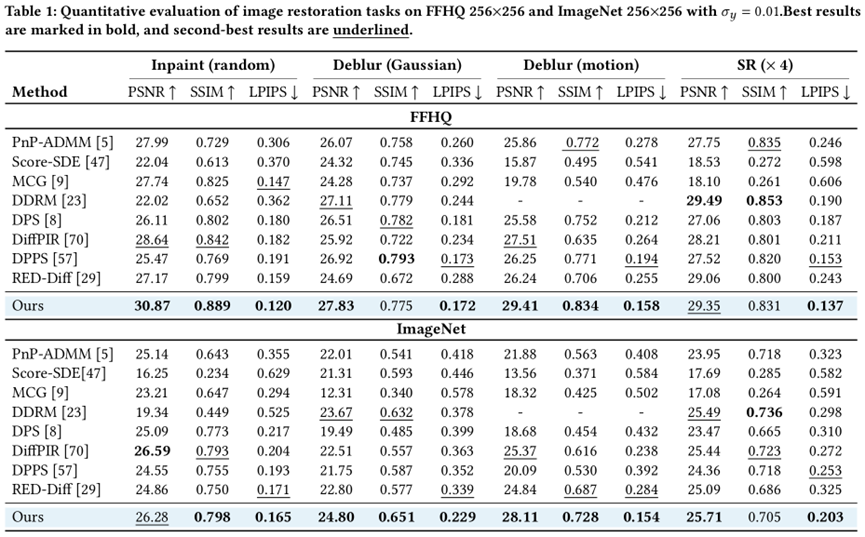
图1: SPGD与现有SOTA方法在FFHQ及ImageNet数据集上的定量结果对比

图2: SPGD与现有方法的图像修复效果可视化比较
实验结果表明,SPGD在各项任务中均取得了顶尖性能。与DPS等主流方法相比,SPGD在峰值信噪比(PSNR)、结构相似性(SSIM)和感知相似度(LPIPS)等关键指标上均实现了显著提升。可视化结果进一步证明,SPGD生成的图像在细节恢复(如头发纹理、物体线条)和伪影抑制方面表现尤为出色,视觉效果远超现有方法。
论文2:Target-Guided Bayesian Flow Networks for Quantitatively Constrained CAD Generation
1. 研究背景
基于深度生成模型的参数化CAD建模技术正在推动工程设计向更高自动化与精度发展。该任务核心在于生成包含离散构型指令(如线、圆、拉伸)和连续参数(如坐标、半径、角度)的操作序列,具备高度结构化与多模态特征。近年来,扩散模型因其强建模能力和可控性,广泛应用于CAD序列生成,通过结构约束、指令嵌入等机制联合建模离散与连续元素,实现复杂几何体的有效生成。
然而,现有方法仍面临两大挑战:(1) 模态耦合障碍:离散指令与连续参数高度相关,但现有扩散模型多为分模态建模,导致逻辑不连贯、类型与参数错位;(2) 参数扰动放大:CAD序列具强因果结构,早期误差易被放大,严重影响后续几何质量与结构可行性。
2. 本文方法:目标引导贝叶斯流网络(TGBFN)
针对CAD程序生成中的模态不一致与误差累积问题,本文提出了目标引导贝叶斯流网络(Target-Guided Bayesian Flow Network, TGBFN)算法。解决模态不一致与误差累积问题。其核心包括三部分:(1)无偏贝叶斯推理:采用多路径并行机制,缓解长序列生成中的误差积累;(2)条件引导贝叶斯流:显式引入几何条件,构建条件后验,引导生成向目标解演化;(3)校准分布估计:通过多次采样与映射校准生成分布,提升几何精度与一致性。
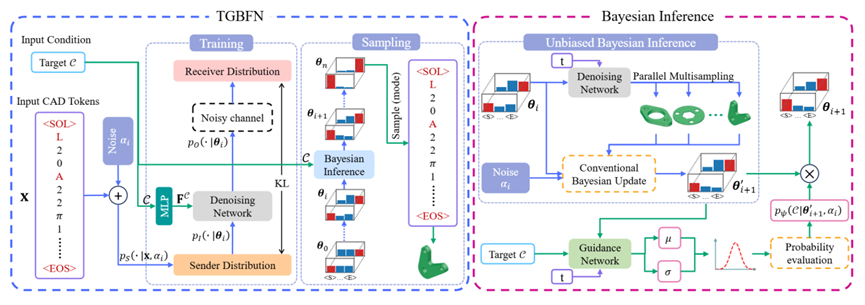
图3:TGBFN框架图
TGBFN通过贝叶斯建模生成满足数值约束的CAD序列,训练时最小化发送器与接收器分布间的KL散度,推理时仅依赖目标条件实现高精度可控生成。
3. 实验结果
本文在参数化CAD设计领域的DeepCAD数据集上,针对定量条件下的高精度CAD生成任务进行了全面的定量与定性评估。
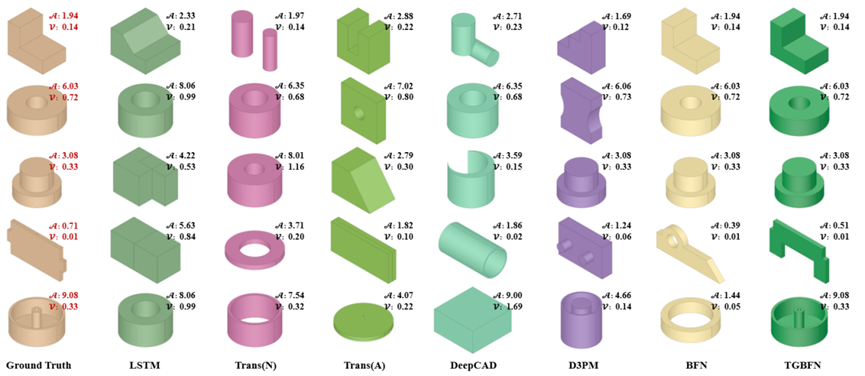
图4:TGBFN与现有方法的生成实例分析
实验结果表明,TGBFN 在定量约束 CAD 生成任务中实现了领先性能。相较于 DeepCAD、D3PM、BFN 等主流方法,TGBFN 在定量条件约束下的关键指标均取得显著提升,误差显著更低,相关性更高。可视化结果进一步表明,TGBFN 所生成的几何结构在细节精度、拓扑完整性和目标属性一致性方面均优于现有方法,特别在复杂结构与极端约束条件下,依然保持高质量输出,展现出卓越的可控性与稳定性。
论文3:Dual Prompt Learning for Adapting Vision-Language Models to Downstream Image-Text Retrieval
1. 研究背景
随着预训练视觉语言模型(VLM)的发展,其出色的零样本学习性能受到了广泛关注。代表性模型如 CLIP ,通过从大规模图像-文本对中学习跨模态表示,构建了一个统一的视觉语义空间,为多种下游任务提供了有力支持。然而,将 VLM 直接应用于特定领域任务时,效果往往依赖于提示模板(prompt)设计的细节,缺乏通用性和鲁棒性。近年来,提示学习作为一种无需修改预训练模型参数的适应范式,在图像分类等任务中取得了显著进展。通过引入可学习的提示,不仅保留了模型的预训练知识,还能利用少量标注样本实现快速适应。
在图文检索任务中,提示学习面临更大挑战。这类任务需要实现细粒度的视觉语义对齐,即准确捕捉图像中的微小属性差异和相似类别间的区分能力。例如,模型需要识别出“Bengal”与“Bombay”的差别,同时理解颜色、动作等局部细节。当前通用的提示学习策略难以直接应对这类复杂的检索需求,因此需要设计更具针对性的方法,以提升视觉-语言模型在下游图文检索任务中的适应能力。
2. 本文方法:双提示学习和属性识别的图文检索方法(DCAR)
为了应对上述挑战,本文提出一种创新的双提示学习框架(DCAR),用于实现精确的图文匹配。该框架从语义和视觉这两个维度动态调整提示向量,以提高CLIP在下游图文检索任务上的性能。DCAR联合优化属性和子类别特征,以增强细粒度表征学习。具体来说,(1)在属性级别,基于文本图像互信息相关性动态更新属性描述部分的计算权重;(2)在相似子类别层面,从多个角度引入负样本来学习子类别的区别,强调了同一元类别子类别之间的细粒度区分。此外我们还构建了一个细粒度子类别描述的图文检索数据集(FDRD),涵盖了1500多个细粒度子类别和23万个带有详细属性标注的图文对。
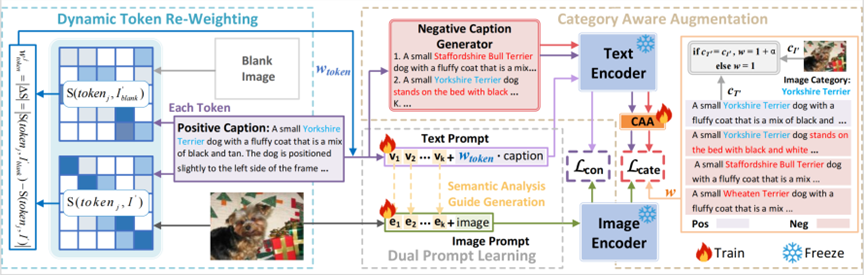
图5: DCAR架构设计
DCCAR通过集成属性感知token重新加权模块和类别感知负样本增强模块来实现精确的图文匹配。
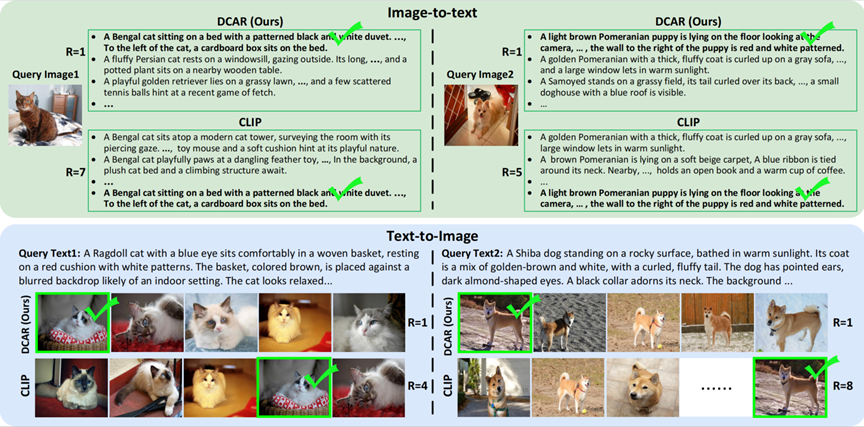
图6: DCAR方法与baseline检索结果比较
DCAR 成功地区分了视觉上相似的子类别, 查询的Top-5结果显示出与查询内容更强的语义相关性。
主要作者介绍:
邬鸿杰,计算机学院三年级博士生,研究方向为神经网络和生成模型。
郑文豪,计算机学院二年级直博生,研究方向为可控3D形状生成。
王一凡,计算机学院二年级硕士生,研究方向为多模态检索、开放语义检测。
刘祥根,四川大学副教授,博士生导师,入选天府峨眉计划青年人才计划,国家重点研发计划“工业软件”课题负责人,四川大学计算机组成与结构虚拟教研室副主任,四川大学学报(自然科学版)青年编委。2021年于清华大学获得博士学位,同年被四川大学人才引进为副教授。研究方向包括文本生成、模式识别、AI药物设计等,在Nature Communications等国际重要期刊会议上发表学术论文 30 余篇。
王韬,四川大学计算机学院副研究员,硕士生导师,研究方向为计算机视觉、深度学习,在权威期刊和会议上发表论文二十余篇,包括 CVPR、ICCV、ECCV NeurIPS、IEEE TIP等。