

我中心科研团队发布鲁班-10B,助力大模型走进制造业
背景介绍
随着通用大模型在自然语言处理领域的快速发展,其在文本生成、问答系统和语言理解等任务中已取得显著成果。然而,在工艺设计等高度专业化的工程场景中,现有大模型的适用性仍面临诸多挑战。工艺设计文本不仅包含大量专业术语和复杂流程描述,还常涉及长文本输入,具有语义层次深、逻辑关系复杂等特点。这对模型的语言理解与上下文建模能力提出了更高要求,同时也加剧了Transformer架构下自注意力机制在处理长序列时的计算压力,其推理效率与显存开销成为工业应用的主要瓶颈。
文章信息
近日,我中心吕建成教授团队在《四川大学学报(自然科学版)》知网优先首发发表了题为《面向工艺设计的领域大模型构建方法》的研究论文,该文章系统地提出并实践了一套面向工艺设计场景的大规模语言模型构建方案,成功构建并训练了100亿参数规模的专业领域大语言模型“鲁班-10B”。我中心刘祥根副研究员与四川大学计算机学院硕士研究生郭彦为论文的共同第一作者,东方电气创新研究公司参与合作。吕建成教授为通讯作者。
作者:刘祥根1 郭彦1 李玥2 孙晨伟1 吕建成1
通信作者:吕建成1
作者单位:1.四川大学计算机学院 2.东方电气(成都)创新研究有限公司
引用本文:刘祥根,郭彦,李玥,等.面向工艺设计的领域大模型构建方法[J]. 四川大学学报(自然科学版), 2025, 62(3). DOI:10.19907/j.0490-6756.250087
成果介绍
本研究提出并实践了一套面向工艺设计领域的大语言模型构建方案,成功训练了具备100亿参数规模的“鲁班-10B”模型。该模型在整体架构上创新性地引入混合稀疏注意力机制,在保障语义表达能力的基础上优化了长文本的处理效率。通过起始词元锁定、关键词元筛选和缓存优化等策略,有效压缩了非核心语义的计算负担,将Transformer自注意力机制的计算复杂度由传统的O(N²)降低至O(n + kN),在降低资源消耗的同时提升了模型对长文本的生成稳定性。
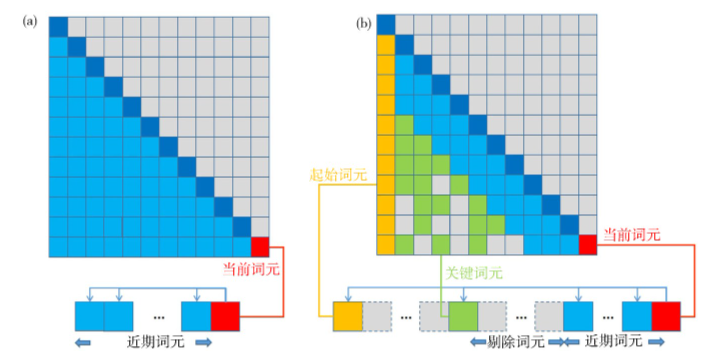
图1 传统注意力机制(左)与混合稀疏注意力机制(右)的对比
在语料构建方面,团队构建了覆盖机械、材料、制造等多个工程方向的高质量领域语料库,并采用“预训练+指令微调”的两阶段训练策略,使模型在具备通用语言能力的基础上,进一步学习工艺设计任务中的语言特征和语义结构。考虑到部署效率与计算资源限制,模型微调阶段引入LoRA(Low-Rank Adaptation)技术,仅对少量参数进行低秩更新,有效降低了模型调优与应用过程中的资源成本。
实验结果显示,鲁班-10B在BLEU(0.457)与Rouge-L(0.644)等文本生成指标上表现优异,生成内容在专业性、逻辑性与表达完整性方面均优于多个主流开源大模型。基于鲁班-10B,研究人员开发了国内首个基于大模型的工艺生成系统(luban.neusym.cn),在工艺流程生成任务中展现出稳定的性能,为大模型在工程制造领域的落地应用提供了有力支撑。