

我中心研究生参加2024IJCAI并现场汇报最新成果
IJCAI2024会议于8月3日至9日在韩国济州岛召开。我中心2023级博士生卢奥军、2022级硕士生宋孝天与2023级硕士生纪晗的三篇论文被IJCAI2024接收,并进行现场汇报,指导老师/通讯作者是我中心孙亚楠教授。IJCAI会议是人工智能领域的重要学术会议,被中国计算机学会评定为A类学术会议(CCF A)。 2024年IJCAI共计收到5651篇投稿,录用率约为14.0%。
论文1:Revisiting Neural Networks for Continual Learning: An Architectural Perspective(2023级博士生卢奥军为第一作者)
背景:持续学习(Continual Learning)旨在赋予神经网络模型持续地学习和更新知识的能力,同时避免对模型现有知识的遗忘。在该领域中,以往的相关研究主要集中在开发新的学习算法,以平衡模型的稳定性和可塑性。这些方法实现了针对持续学习目标优化参数。然而,现有方法通常基于现有的网络架构,限制了架构探索的视野,未能实现优化网络架构设计以适应持续学习。

图1 论文现场汇报
研究方案与创新:为了填补现有研究的空白,课题组系统地研究了网络架构设计对持续学习的影响,包括网络规模和网络组件等。具体来说,通过设计一系列对比实验,研究得到了以下发现:(1)相较于其它下采样方式,最大池化可以达到最佳的持续学习性能;(2)全局平均池化层在两类持续学习场景中展现了截然不同的作用,即有利于类增量场景但会损害任务增量场景的模型性能;(3)增加神经网络的宽度可以显著提升其持续学习性能,而增加深度则没有明显益处。此外,为了进一步探索研究架构在持续学习中的作用,论文基于以上研究发现,应用神经架构搜索(Neural Architecture Search)方法为两类场景设计了更适合持续学习的网络架构。
实验验证:论文将设计得到的神经网络架构与现有的基准架构进行对比,以突出架构在持续学习中的重要作用。部分实验结果如下所示,更多实验结果请参考论文。
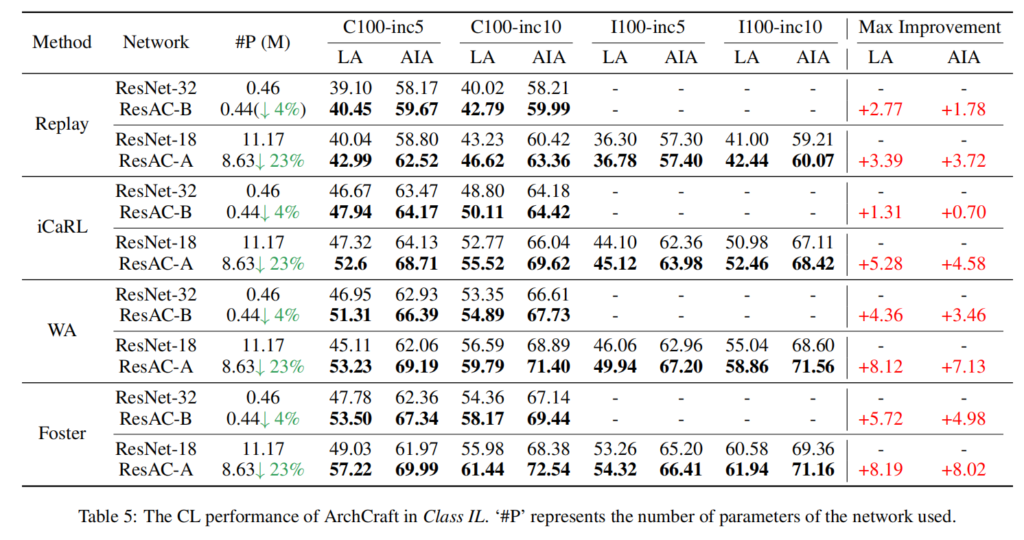
图2 重新设计后的架构(ResAC)与基准架构在类增量场景下的持续性能对比
总结:该工作为研究持续学习提供了一个新颖的架构视角,即通过架构的革新克服灾难性遗忘。研究表明,合适的架构与有效的学习方法对持续学习性能同样重要。特别是,应用持续学习友好的架构可以在更少的参数量下,同时增强稳定性和可塑性,从而实现更优的持续学习性能。
论文2:One-step Spiking Transformer with a Linear Complexity(2022级硕士生宋孝天为第一作者)
背景:脉冲Transformer近年来在多个任务中展现出了优异的性能,包括图像分类和目标检测等领域。然而,现有脉冲Transformer仍然依赖于冗长的模拟时间步来捕捉脉冲信号的动态变化,导致了模型训练和推理过程中的延迟。此外,现有脉冲Transformer模型中的自注意力机制通常基于复杂的浮点运算,这进一步增加了模型的功耗和计算资源需求。

图3 论文现场汇报
方法与创新:为了解决上述挑战,课题组提出One-step Spiking Transformer(OST)模型,将多个冗长时间步减少为只有1个。具体来说,通过时域压缩和补偿(Time Domain Compression and Compensation, TDCC)来减轻时空开销。其中压缩操作是指将T个时间步的信息压缩为一个时间步信息,从而大幅降低计算成本。由于压缩操作不是无损操作,随后的补偿能够弥补时域中的信息损失。将两者结合起来,TDCC可以充分利用时空信息,实现与压缩前相似性能,而且成本更低。此外,通过引入尖峰线性变换(Spiking Linear Transformation, SLT),能够避免使用二次复杂度的自注意机制。SLT由ASF和SGFF组成,其中SAF能够消除了自我注意的浮点点乘计算,而SGFF可以将浮点元素乘积转换为二进制逻辑与 (&)运算。
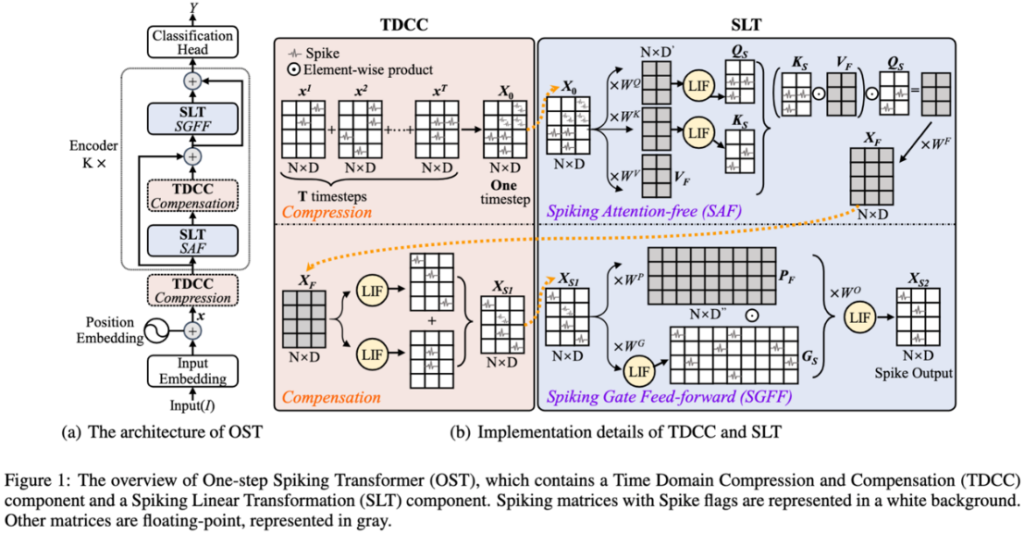
图4 OST模型整体框架图
实验验证:文章采用静态数据集和神经形态数据集从多角度对所提的OST模型的有效性进行了验证。部分实验结果如下所示,更多实验结果请参考论文。
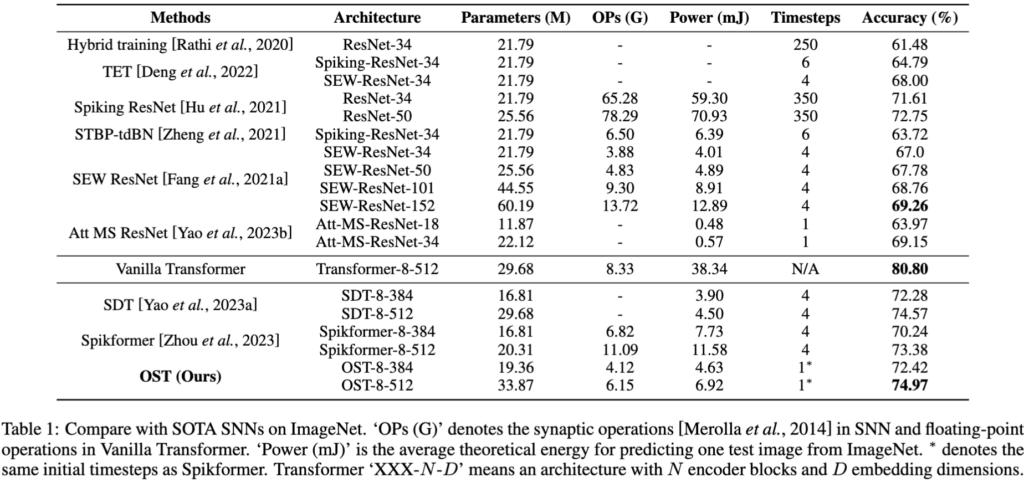
图5 OST在静态数据集ImageNet上的性能
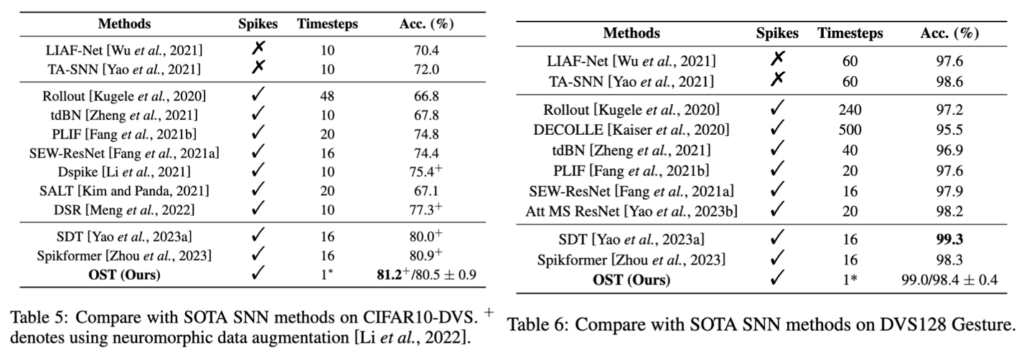
图6 OST在动态数据集CIFAR10-DVS和DVS128 Gesture上的性能
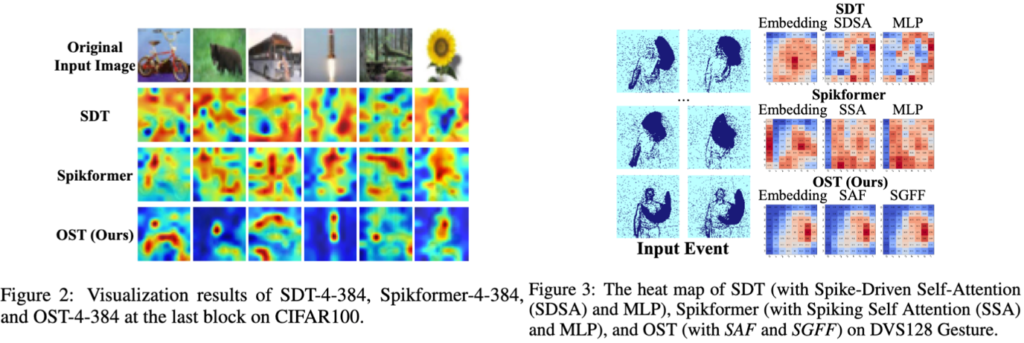
图7 OST模型可视化对比实验结果
总结:该工作从减少先有脉冲Transformer功耗的角度出发,通过设计压缩与补偿方法,显著降低了模型的时间步长。此外,通过设计的脉冲线性变化组件,进一步减少了脉冲操作数目,降低了模型整体功耗。实验结果表明:1)OST在静态数据集和神经形态数据集上表现均优于或与现有最有模型性能近似;2)OST 运行速度更快,尤其是当时间步长T大于等于4时尤为明显;3)OST 性能更好,特别是在小时间步长(T小于4)的情况下;4)OST 对减少时间步长不敏感度(即使只有一个时间步数)。综上所述,OST可以成为现有脉冲Transformer的有力替代者。
论文3:CAP: A Context-Aware Neural Predictor for NAS(2023级硕士生纪晗为第一作者)
背景:性能预测器可直接预测未见过架构的性能,大大加速了神经架构搜索(Neural Architecture Search, NAS)中耗时的性能评估过程。然而,现有预测器依然依赖足量架构-性能数据对进行训练才可实现精准评估,获取大量架构-性能数据的过程导致了高昂的计算成本。

图8 论文现场汇报展示
方法与创新:为了解决这一问题,课题组提出Context-Aware Neural Predictor (CAP)模型,利用上下文感知的自监督任务构建了一个仅需少量训练数据对的性能预测器。具体来说,先将输入架构用图数据表示,其中节点代表架构的操作类型而边代表架构内的连接方式。接着,上下文感知的自监督任务先从大量无标注的图数据中分别提取K跳中心子图和上下文图,构成图样本对。其中正样本对的中心子图和上下文图来自同一原始图,而负样本对的则来自不用原始图。预测器通过分辨上述正负样本对,可充分挖掘架构中的属性和结构信息,有利于学习到更具表达性的架构表征。最后,仅需少量标注数据进行微调,即可构建一个精确高效的性能预测器。
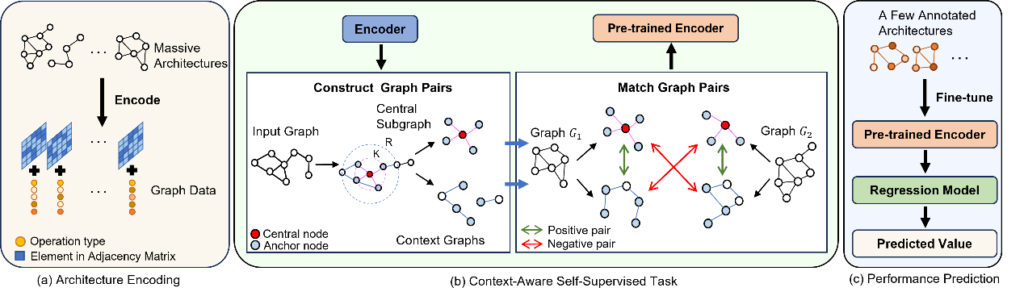
图9 CAP方法流程图
实验验证:文章从排名能力和帮助NAS搜索最优架构两个方面验证了所提的CAP模型的有效性。部分实验结果如下所示,更多实验结果请参考论文。
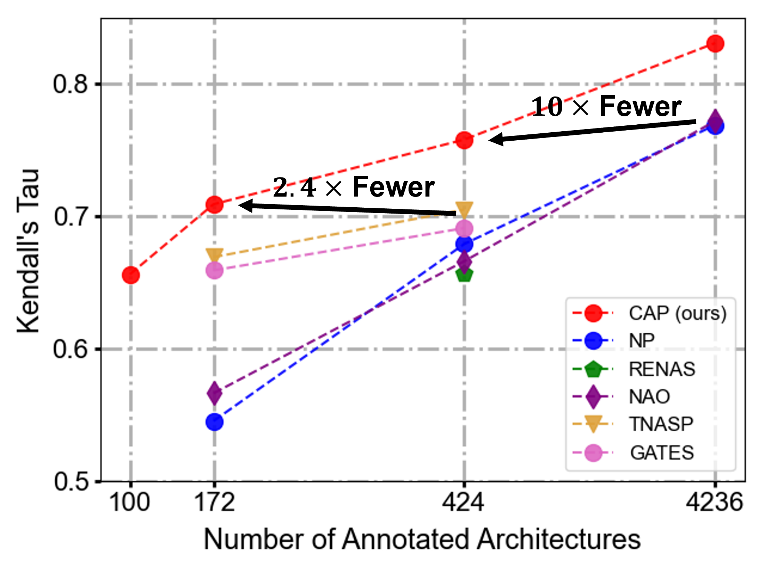
图10 CAP在NAS-Bench-101上的架构排名表现

图11 CAP搜索的最优架构在CIFAR10数据集上的表现

图12 CAP中自监督任务的消融实验
总结:该工作从减少现有预测器对标注数据依赖的角度出发,通过设计一个上下文感知的自监督任务,仅用少量训练数据构建了一个高效精确的预测器。和现有预测器相比,CAP可在使用更少训练数据的条件下,拥有同等甚至更精准的架构排名能力。文章通过在多种实验设置下,验证了所提出CAP的有效性。