

我中心在聚类新范式和开集图像复原研究中取得进展,相关成果发表于ICML
近日,我中心彭玺教授课题组在International Conference on Machine Learning(ICML)上发表两篇论文,其中一篇论文入选Oral。ICML是机器学习领域的国际顶级会议。ICML 2024共计收到9473篇投稿,录用率约为27.5%,其中Oral论文仅144篇,录用率约1.5%。
2020级直博研究生李云帆为第一作者,彭玺教授为通讯作者,录用的ICML Oral论文“Image Clustering with External Guidance”在国际上首次提出了外部引导的聚类新范式,从预训练CLIP模型的文本模态中挖掘语义信息,构建其与给定图像集之间的关联,从而显著提升了图像聚类性能。
2021级博士研究生缑元彪为第一作者,彭玺教授为通讯作者,录用的ICML论文“Test-Time Degradation Adaptation for Open-Set Image Restoration”在国际上首次研究了开集图像复原问题,旨在通过单个模型在测试时去解决多种未知且训练时未见过的图像退化,为处理现实世界中不可知且不可预见的图像退化提供了首个思路。
论文1:Image Clustering with External Guidance
背景:作为机器学习的经典任务之一,图像聚类旨在无需依赖样本标注的情况下,将图像依据语义划分到不同的类簇中,其核心在于利用先验知识构建监督信号。从经典基于类簇紧致性的k-means到近年来基于增广不变性的对比聚类[1],聚类方法的发展本质上对应于监督信号的演进。
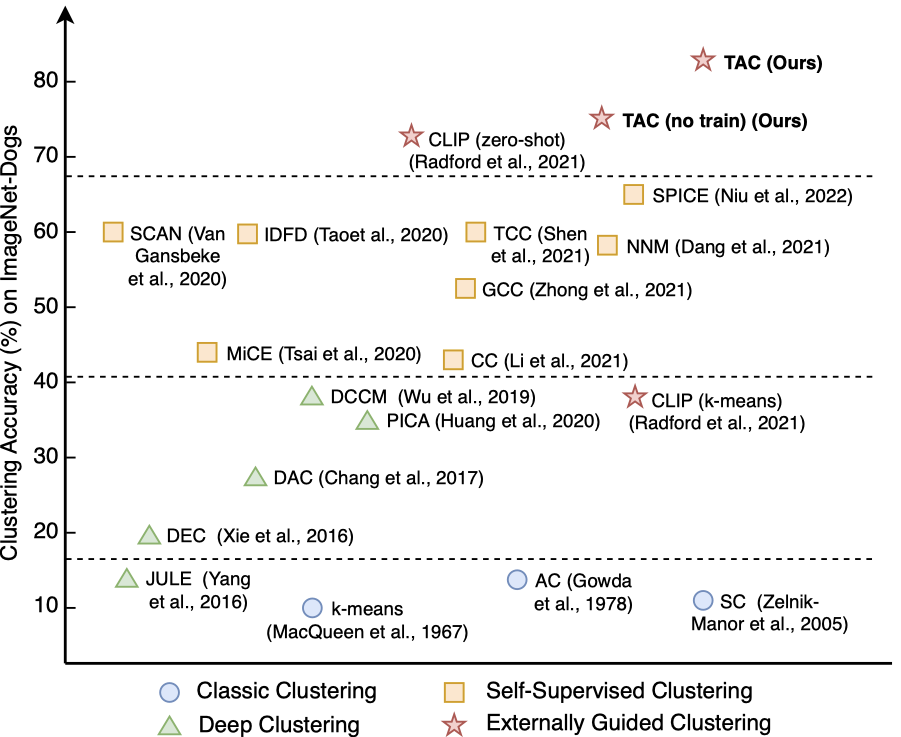
图1: 聚类方法的发展大致可分为三个阶段: (1)传统聚类,基于数据分布假设设计聚类策略; (2)深度聚类,利用深度神经网络提取有利于聚类的特征。彭玺教授及合作者在2015年提出了国际上最早的三个深度聚类方法之一; (3)自监督聚类,通过数据增广或动量网络等策略构建自监督信号,该领域的开创工作是彭玺教授课题组2021年提出的Contrastive Clustering,自发表以来是聚类领域引用最高的论文。不同于此前的工作聚焦于从数据内部挖掘监督信号,本文提出利用外部知识来引导聚类,并将新范式归类为 (4)外部引导聚类。实验结果表明,通过利用文本模态中的语义信息,所提出的方法(TAC)显著提升了图像聚类精度。
现有的聚类研究虽然在方法设计上各不相同,但均是从数据内部挖掘监督信号,其性能最终会受限于数据自身所蕴含信息量的固有上限。举例来说,柯基和巴哥犬的图片有明显的差异,但其和柴犬在外观上十分相似,仅依据图像本身难以对二者进行区分。但值得注意的是,在数据内蕴信息之外,现实世界中还存在着大量有助于聚类的外部知识,而在现有工作中被很大程度地忽略了。在上述例子中,假设模型具备来自知识库的“柯基腿较短,而柴犬腿较长”等非图像域的外部先验,则能更准确地对二者的图像进行区分。换而言之,与从数据中竭力地挖掘内部监督信号相比,利用更加丰富且容易获得的外部知识来引导聚类,有望起到事半功倍的效果。
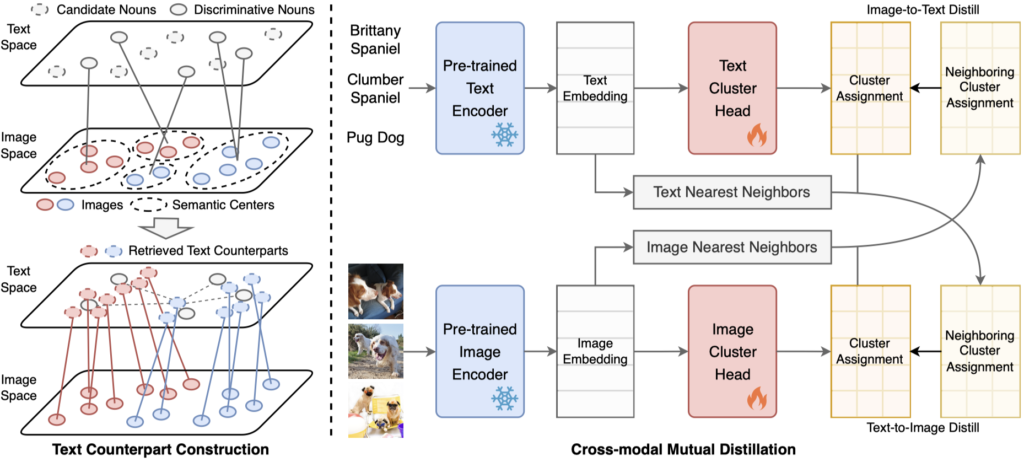
方法:论文提出了一种简单而有效的外部引导聚类方法TAC(Text-Aided Clustering,文本辅助的聚类),基于预训练CLIP模型,通过利用来自文本模态的外部知识辅助图像聚类。在缺乏类别标注和图片描述等文本信息的情况下,利用文本语义辅助图像聚类面临两个挑战:(1)如何构建图像的文本表征;(2)如何协同图像和文本进行聚类。
具体地,针对挑战(1),与常见的CLIP Zero-shot分类相反,TAC将WordNet[2]中的名词划分到k-means计算得到的图像语义中心,并保留每个语义中心对应概率最高的名词,作为组成文本空间的候选词。之后,TAC为每张图像检索其最相关的名词来构建其文本模态的表征。此时,仅需将文本和图像表征进行简单拼接即可提升表征的判别性,在无需任何的额外训练和模型调优的情况下显著提升k-means的图像聚类性能。针对挑战(2),为充分协同文本和图像两个模态,TAC提出跨模态互蒸馏方法,利用跨模态邻居之间的聚类指派一致性训练额外的聚类网络,以进一步提升聚类性能。
实验:本文在五个经典数据集和三个更具挑战性的图像聚类数据集上对方法进行了验证,部分实验结果如下:
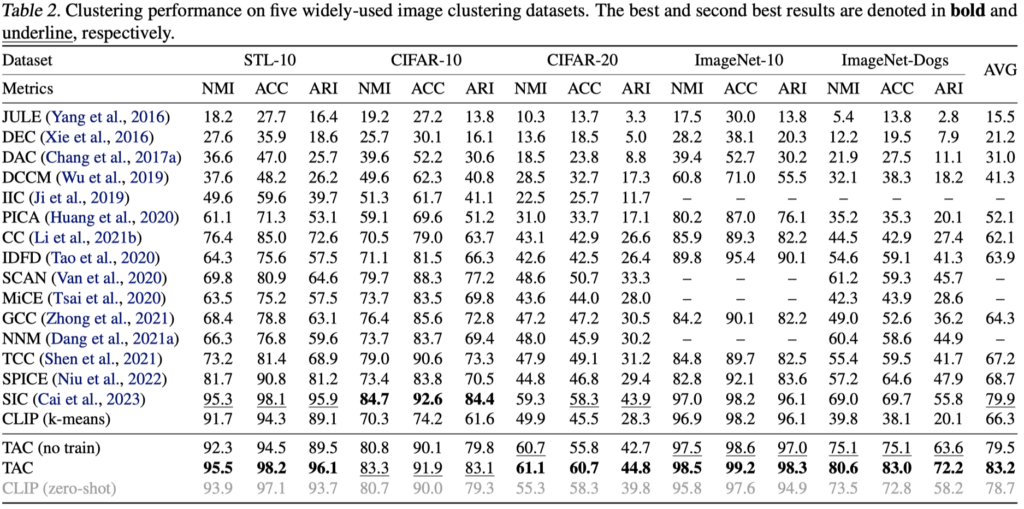
表1:所提出的TAC方法在经典图像聚类数据集上的聚类性能
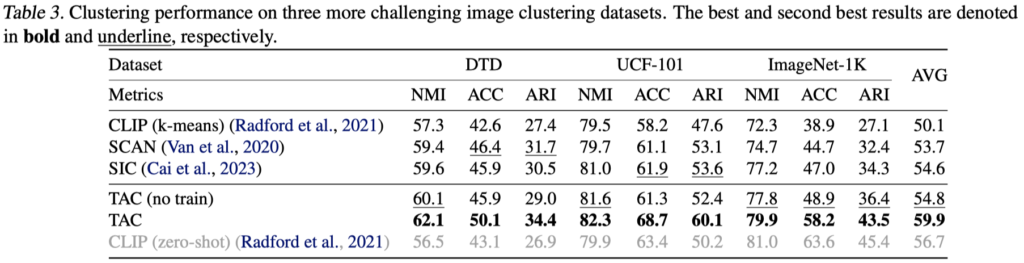
表2:所提出的TAC方法在更具挑战性的图像聚类数据集上的聚类性能
从结果中可以看出,在缺少标注信息的情况下所提出的TAC方法通过为每个图像构建文本表征,能够有效地从文本模态中挖掘语义信息。在无需任何额外训练的情况下,TAC (no train)显著提高了直接在CLIP提取的图像表征上使用k-means聚类的性能,特别是在更困难的数据集上。当进一步使用提出的跨模态相互蒸馏策略训练聚类网络时,TAC取得了最优的聚类性能,甚至超过了依赖类别标签信息的CLIP Zero-shot分类性能。
总结:不同于现有的聚类研究聚焦于从数据内部构建监督信号,本文创新性地提出利用此前被忽略的外部知识来引导聚类。所提出的TAC方法在无需文本描述的情况下,从预训练CLIP模型的文本模态挖掘语义信息,显著提升了图像聚类性能,证明了所提出的外部引导聚类新范式的有效性。
所提出的外部引导聚类范式的挑战在于:1)如何选择合适的外部知识;2)如何有效的整合外部知识以辅助聚类。除了本工作关注的文本语义外,外部知识广泛存在于各类的数据、模型、知识库等,对于不同的数据类型和聚类目标,需要针对性地选择与利用外部知识。总的来说,在目前大模型、知识库日趋成熟背景下,外部引导的聚类新范式具备良好的发展潜力,这也是彭玺教授团队近期引领外部引导无弱监督学习新范式的标志性方向之一。
论文2:Test-Time Degradation Adaptation for Open-Set Image Restoration
背景:图像复原旨在消除图像中的退化现象(如噪声、模糊和雨雾),提升图像的视觉效果和信息内容。近年来,图像复原方法取得了显著进展,能够处理多种多样的退化问题,例如高斯噪声、运动模糊、低分辨率等。尽管这些方法取得了不错的性能,但大都面向封闭场景,即假设测试时的图像退化与训练时的图像退化是相似的。然而,这种假设在实际应用中往往是不成立的。实际场景中的图像退化情况复杂多变,可能由于设备差异、环境因素或人为干扰等,导致在测试时出现的退化是未知的,并且是在训练数据中没有见到过的。
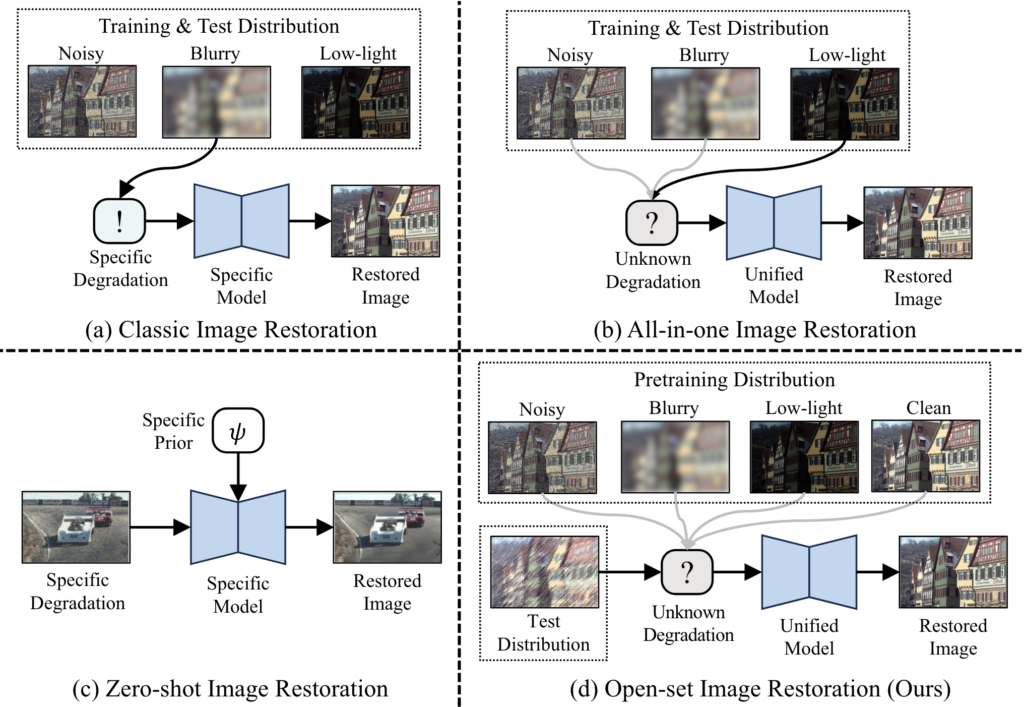
图1:不同图像复原任务之前的区别。(a)经典任务主要面向一种封闭场景,即训练和测试的图像退化是相同且已知的,需要为每种退化定制一个专门的模型;(b)多合一任务也面向一种封闭场景[4],即训练和测试的退化集合是相同的,但需要通过单个模型解决集合中包含的多种未知退化;(c)零样本任务专注于从单张退化图像中直接进行复原[5],但通常是面向特定退化进行设计,并利用特定的先验知识进行辅助;而本文提出的(d)开集任务主要面向开放场景,其中测试退化是未知的并与训练时的退化不同,需要通过单个模型去解决多种未知且训练时未见过的图像退化。
方法:针对上述问题,本文研究了一个更具挑战性且未被涉足的问题:开集图像复原(OIR)。不同于封闭场景下的方法仅解决训练阶段遇到的特定退化,OIR要求模型去处理训练数据中不存在的未知退化。为此,我们在该工作中研究并揭示了OIR问题的本质,即测试和训练数据之间的未知分布偏移。针对这一问题,测试时适应(TTA)作为一种有效方法应运而生,以解决测试数据与训练数据之间固有的差异[3]。简单来说,它在测试阶段根据测试数据来调整预训练模型的参数,使模型能够在更广泛的输入场景中表现更好。
基于此,我们提出了一个用于开集图像复原的测试时退化适应框架TAO。它利用TTA的思想为OIR问题提供了一种可行的解决方案。具体地,该框架包括三个组成部分:一个预训练的图像扩散模型(PDM)、一个测试时退化适配器(TDA)和适配器引导的图像恢复(AIR)。PDM被采用为解决OIR问题的基础模型主要基于以下考虑。首先,PDM具备生成各种高质量视觉场景的丰富知识,可以被视为产生干净图像的通用预训练模型。其次,PDM是退化无关的,测试数据的任何退化都可被视为未见过的。在PDM的每个去噪步骤之后,TDA和AIR依次执行,分别用于适应开集场景和指导图像恢复。具体地,TDA在测试阶段采用一个可学习的适配器来适配PDM到测试退化图像上。这个适配器被设计用于域对齐,将PDM的生成域与测试图像的退化域对齐。这样,生成的干净图像可以被转换为相应的退化图像,然后可以进一步被引导更新以生成对应的干净图像。AIR被设计来进行这种监督更新,通过在不同的PDM去噪步骤中动态地调整引导更新策略,以实现更好的图像恢复。
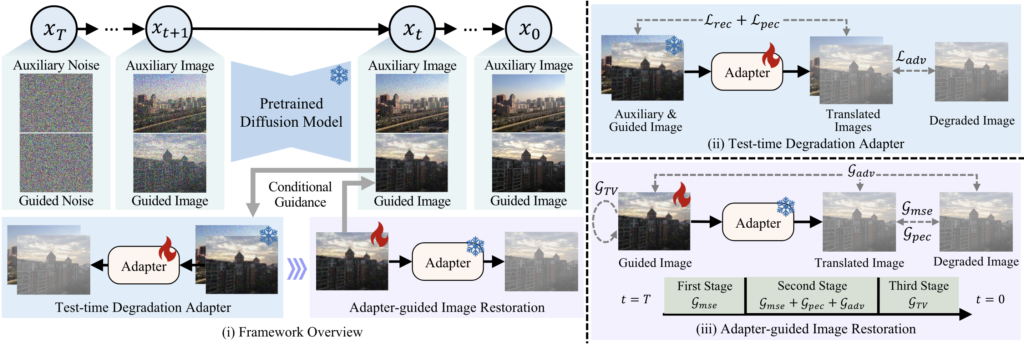
图2:所提出的TAO框架利用(i)预训练扩散模型(PDM)作为OIR的通用预训练模型,并在每个去噪步后,首先执行(ii)测试时退化适配器(TDA)以适应开放场景中未知和未见过的退化,然后进行(iii)适配器引导的图像复原(AIR)以引导生成图像成为复原出的干净图像。注意:雪花表示图像或模型是固定的,火焰表示图像或模型将通过梯度进行更新。
实验:我们在多种退化类型上验证了TAO框架在处理OIR问题时的有效性,包括图像去雾、低光照图像增强和图像去噪任务。结果显示,其在多个评价指标上与为任务专门设计的方法相比,取得了同等甚至更优的性能。部分实验结果如下,更多实验请参考论文。

表1. 在HSTS数据集上的图像去雾结果。我们的方法优于零样本方法,并获得了与经典有监督学习方法相当甚至更好的结果。所有比较的方法都是专门为图像去雾设计的。

图3. 图像去雾的视觉结果,从中可以观察到现有方法过度去雾导致图像变暗和/或产生伪影。相比之下,我们的方法获得了更清晰、更接近自然真实的结果。

表2. 在LOL数据集上低光照图像增强结果。我们的方法在零样本方法中获得了最佳的SSIM值和第二好的PSNR值,并只有监督学习的MBLLEN在这两个指标上同时优于我们的方法。

图4. 低光照图像增强的结果,从中可以看到我们的结果既不像MBLLEN那样平滑,也不像ZDCE那样暗淡。尽管存在轻微的颜色偏差,我们的方法实现了对低光照图像的合理照明。
总结:该工作从实际出发,揭示并正式定义了开集图像复原问题(测试退化是未知的并与训练时的退化不同,且通过单个模型去解决多种未知且训练时未见过的图像退化)。为了解决这个问题,本工作从分布偏移的角度揭示了其本质,并发现测试时适应是解决这种固有偏移的有效方法。因此,我们提出了一个用于开集图像复原的测试时退化适应框架,其巧妙之处在于以下几点:首先,它考虑了一个预训练的图像扩散模型作为解决各种图像复原任务的通用预训练模型;其次,它引入了一个在测试阶段优化的适配器,用于使预训练模型适应未知和未见过的测试退化;第三,它根据去噪过程动态调整引导策略,获得了更好的复原结果。通过在多种退化上的实验,我们展示了这些设计的有效性。
自2022年彭玺教授课题组在国际上率先提出多合一图像复原问题(即训练和测试的退化集合是相同的,但需要通过单个模型解决集合中包含的多种未知退化),该研究方向已成为影像复原和增强领域的近年来最受关注的新方向之一。开集影像复原是彭玺教授课题组提出的多合一影像复原任务面向真实开放世界的进一步延伸和靠近,有望给领域提供新的洞见和理解。
参考文献:
[1] Yunfan Li, Peng Hu, Zitao Liu, Dezhong Peng, Joey Tianyi Zhou, and Xi Peng*, Contrastive Clustering, Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI’21), Feb. 2-9, 2021.
[2] Miller G A. WordNet: a lexical database for English[J]. Communications of the ACM, 1995, 38(11): 39-41.
[3] Wang, D., et al. Tent: Fully test-time adaptation by entropy minimization. In Proceedings of the International Conference on Learning Representations, 2021.
[4] Boyun Li, Xiao Liu, Peng Hu, Zhongqin Wu, Jiancheng Lv, Xi Peng*, All-In-One Image Restoration for Unknown Corruption, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA. Jun. 19-25, 2022.
[5] Boyun Li#, Yuanbiao Gou#, Shuhang Gu, Jerry Zitao Liu, Joey Tianyi Zhou, and Xi Peng*, You Only Look Yourself: Unsupervised and Untrained Single Image Dehazing Neural Network, International Journal of Computer Vision (IJCV), 2021.