

我中心自然语言处理与大语言模型研究获得新进展
我中心雷文强教授在自然语言处理与大语言模型领域取得一系列重要突破,相关研究成果被国际计算语言学顶级学术会议——ACL 2024接受。ACL是自然语言处理和计算语言学领域最具影响力的盛会,被中国计算机学会(CCF)推荐会议列表列为 A 类会议。
雷文强教授长期专注于人机交互和结构化知识表征技术研究。在人机交互层面,本次被ACL 2024接收的论文聚焦评估和提升大模型的主动性对话能力,使得大模型在面对用户歧义查询时能主动阐明用户指令中的歧义性,借此打造更自然、高效的人机协作方式,提升大模型的交互能力和用户体验;在结构化知识表征层面,论文以流程自动化为场景,旨在增强大模型的知识表示和推理能力,促进大模型的可解释性和可控性,推动大语言模型在理解和运用人类知识方面取得突破。以下为ACL 2024接收论文及其具体介绍。
一、论文成果:
[1] CLAMBER: A Benchmark of Identifying and Clarifying Ambiguous Information Needs in Large Language Models, ACL 2024 (主会)
[2] PAGED: A Benchmark for Procedural Graphs Extraction from Documents, ACL 2024 (主会)
[3] CARE: A Clue-guided Assistant for CSRs to Read User Manuals, ACL 2024 (主会)
[4] ARAIDA: Analogical Reasoning-Augmented Interactive Data Annotation, ACL 2024 (主会)
[5] Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models’ Understanding of Discourse Relations, ACL 2024 (主会)
[6] STYLE: Towards Tailored Strategy of Asking Clarification Questions to Achieve Effective Domain Transferability, ACL 2024 (Findings)
二、成果介绍:
面向大模型的人机交互方向。论文“CLAMBER: A Benchmark of Identifying and Clarifying Ambiguous Information Needs in Large Language Models” 系统性地针对大语言模型,建立了首个歧义解析能力评估体系。尽管大语言模型已具备良好的问题解答能力,但其在面对用户歧义查询时缺乏主动阐明和澄清的能力,往往倾向于猜测用户意图,并给出与实际需求不符的答案,进而损害用户交互体验和信任度。因此,本论文旨在构建一个针对大语言模型的歧义解析能力评估体系,以全面评测当前模型在识别和澄清模糊用户查询方面的实用性。实验结果表明,现阶段大语言模型在识别和澄清模糊用户查询方面的实用性仍然不足。即使通过思想链(CoT)和少量样本增强提示,模型的提升也较为微弱,且这些技术可能导致部分模型过度自信。此外,由于缺乏冲突解决机制和对固有知识的准确利用,当前大语言模型在提出高质量的阐明性问题方面也存在不足。本论文旨在作为一项测试基准,推动大语言模型在阐明歧义方面的研究,为未来构建更主动、更可信的大语言模型指明方向。

论文“ARAIDA: Analogical Reasoning-Augmented Interactive Data Annotation” 探索了人机交互在数据标注任务中的潜力。传统的 人工数据标注是一项耗时且人力成本高昂的任务。为了解决这一问题,交互式数据标注利用标注模型为人工标注提供建议。然而,当标注模型产生错误的建议时,人工校正将产生额外成本。为了应对这一挑战,本论文提出了一种基于类比推理的方法,旨在提高标注模型的准确性,从而进一步降低人工成本。实验结果表明,该方法能够适应不同的标注任务和标注模型,并能有效降低人工校正成本,平均降低幅度为11.02%。
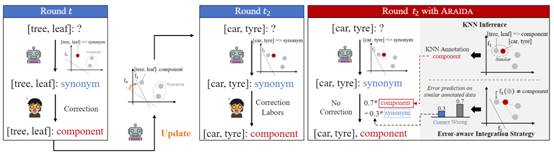
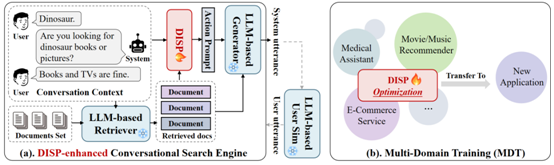
同时,论文“STYLE: Towards Tailored Strategy of Asking Clarification Questions to Achieve Effective Domain Transferability” 深入探讨了如何提升基于大语言模型的阐明性策略框架在不同搜索领域的迁移能力。该研究通过对现有大语言模型策略框架迁移性的深入分析,发现其核心问题在于缺乏执行领域定制化策略的能力。基于此,论文提出了一种结合外部跨领域策略插件和多领域训练范式的新方法,为大语言模型策略框架赋予强大的策略定制化能力,从而显著提升其跨领域迁移能力。这一研究成果推动了对大语言模型策略能力的深入理解,为提升大语言模型跨领域策略的相关工作提供了新的思路和方法。
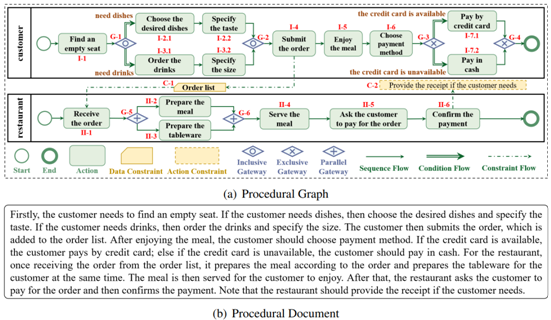
在面向大语言模型的结构化知识表征方向。论文“PAGED: A Benchmark for Procedural Graphs Extraction from Documents” 旨在研究高泛化性与高表征能力的最佳流程图自动化提取技术。自动提取文档中的流程图能够为用户提供一种低成本的流程理解方式,使其能够通过浏览可视化流程图轻松理解复杂的流程。尽管近期的研究在该领域取得了一定进展,但两个重要问题尚待解决:1. 现有研究是否有效地解决了该任务;2. 新兴的大语言模型是否能为该任务提供更好的解决方案。为此,本研究提出了一套全新的基准测试——PAGED,并为其配备了高质量数据集和评估标准。通过对五个最先进的基线模型的深入调研,发现它们未能有效提取最佳流程图,因为其严重依赖于手工规则和有限的可用数据。本研究随后在PAGED中引入了三种先进的大语言模型,并采用了一种新颖的自我完善策略对其进行增强。结果表明,现有大语言模型在识别流程元素方面展现出优势,但在构建逻辑结构方面存在缺陷。PAGED旨在成为流程图自动化提取领域的重要里程碑,并促进对复杂流程图中非序列元素之间逻辑推理的研究。
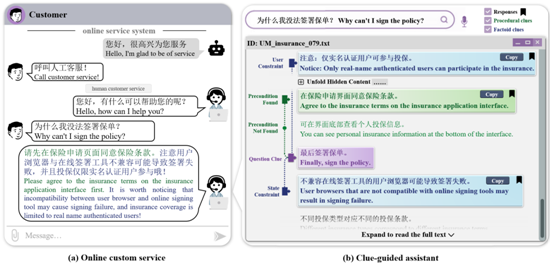
进一步,论文“CARE: A Clue-guided Assistant for CSRs to Read User Manuals” 旨在利用自动化构建的流程图来辅助人工客服回答用户的复杂问题。阅读用户手册,特别是信息量丰富的手册,对于人工客服而言是一项繁琐的任务。构建阅读助手能够显著提高服务效率和质量。然而,现有的解决方案由于缺乏对用户问题和潜在答案的关注,并不适用于在线客服的服务场景。本研究提出为在线人工客服开发一种用户手册阅读助手,该助手能够帮助客服通过明确的线索链快速从用户手册中找到问题的正确答案。每条线索链均通过对用户手册进行推理生成,从与用户问题对齐的问题线索开始,最终指向可能的答案。为了克服监督数据不足的挑战,本研究采用自监督策略进行模型学习。离线实验表明,该方法能够有效地从用户手册中自动推断出准确的答案。在线实验进一步证明了该方法在减轻客服阅读负担和保持高服务质量方面的优势,具体表现为在ICC得分保持在0.75以上的情况下,客服所需时间减少了35%以上。
论文“Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models’ Understanding of Discourse Relations” 深入分析并揭示了大语言模型在篇章语义理解方面的可靠性问题。通过本文提出的基于问答的篇章语义理解可信度评估方法,研究发现,尽管大语言模型如ChatGPT在篇章语义分类任务上取得了显著的性能提升,但其可靠性并不尽如人意,仅为41%。同时,研究表明,语言中明确的话语连接词和上下文信息能够有效提升大语言模型在篇章语义理解方面的可靠性。

部分作者介绍

张桐,二年级硕士生,导师为雷文强教授。主要研究方向为对话式/交互式人工智能,在自然语言处理国际顶级会议EMNLP(CCF-B/清华A类)、ACL(CCF-A)上发表2篇一作论文。

陈悦,二年级硕士生,导师为雷文强教授。该生主要研究方向为对话式/交互式人工智能和信息检索,在自然语言处理国际顶级会议EMNLP(CCF-B/清华A类)、ACL(CCF-A)上发表2篇一作论文。

杜伟宏,二年级硕士生,导师为雷文强教授。该生主要研究方向为结构化知识表征和流程自动化,在自然语言处理国际顶级会议ACL(CCF-A)上发表2篇一作论文。

雷文强,四川大学教授、博士生导师、四川大学计算机学院(软件学院、智能科学与技术学院)院长助理,国家级高层次人才。博士毕业于新加坡国立大学,主要从事自然语言处理,信息检索,大语言模型相关研究。发表中国计算机学会A类长文(CCF-A)等顶会顶刊论文数十篇,多篇一作论文短时间内引用过百,成为国际上该领域主流参考文献。其担任通讯作者的论文获得国际多媒体最高级会议ACM 2020最佳论文奖(1700篇中选一篇)。与荷兰皇家科学院院士Maarten de Rijke教授等世界一流学者联袂在国际顶级会议SIGIR2020和Recsys2021上作关于“对话式推荐系统”三小时Tutorial,其中SIGIR2020 tutorial单场听众超过1600次,为当场听众最多。
担任各大顶级国际会议ACL,KDD,AAAI,IJCAI,WSDM,EMNLP等的(高级)程序委员会委员,担任自然语言处理各大顶会如ACL、EMNLP、COLING领域主席,担任新加坡全国自然语言处理会议SSNLP2021的程序委员会主席和IEEE 旗下国际会议DSS 2022 的Workshop 主席。担任重要期刊ACM Trans. on Web的客座编委,担任国内外顶级期刊比如IEEE Trans. on IEEE Trans. on Knowledge and Data Engineering, ACM Trans. on Information System,《中国科学:信息科学》等审稿人。主持国家自然科学基金面上及以上项目多项,担任多项国家重要项目的评审。积极推进前沿科学研究的实际落地,其研发的技术在政府机构、大型央国企、头部互联网企业等有广泛应用。