

团队成员关于小样本学习的研究取得新进展,相关成果发表在CVPR上
近期,团队成员在小样本学习领域取得了新的研究进展,相关成果已被The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024(CVPR2024)接收。CVPR会议作为计算机视觉领域三大顶会之一,是人工智能领域的重要学术会议,被中国计算机学会评定为A类学术会议(CCF-A)。本届CVPR会议的论文接收率约为22.67%,相比去年25.78%的接收率,难度相对增加。
CVPR2024选入的论文“Simple Semantic-Aided Few-Shot Learning” 由四川大学独立完成,我院2021级硕士研究生张海为第一作者,2020级硕士研究生徐浚哲为共同第一作者,贺喆南教授为通讯作者。该研究提出了一种基于语义进化的小样本学习算法,能够充分挖掘小样本学习中语义信息的潜力。
论文概要:在计算机视觉领域中,从有限数据学习,即小样本学习(Few-Shot Learning),是一项颇具挑战性的任务。若干研究工作利用语义信息并设计复杂的语义融合机制,以弥补受限数据中稀有代表性特征的不足。然而,单纯依赖如类别名称等直观语义往往会因表达过于简洁而引入偏差,而从外部知识库获取大量详尽语义则需要消耗巨大的时间和精力,这一局限性严重制约了语义在小样本学习中的应用潜力。基于此,本文提出了一种基于语义进化(Semantic Evolution)的自动化方法,旨在生成高质量的语义表示。通过融入这种高质量语义,可以减少对先前研究中所采用的复杂网络结构和学习算法的依赖。因此,本文采用了一个简化的两层网络结构,即语义对齐网络(Semantic Alignment Network),用于将语义和视觉特征转化为具有丰富判别特征的鲁棒的类原型。
创新点:
· 至今为止,这是首次考虑通过自动方式收集高质量语义信息并将其应用于小样本学习领域。
· 设计了一种简洁且高效的框架,无需任何复杂的语义理解模块即可将高质量语义信息和视觉特征转化为鲁棒的类原型。
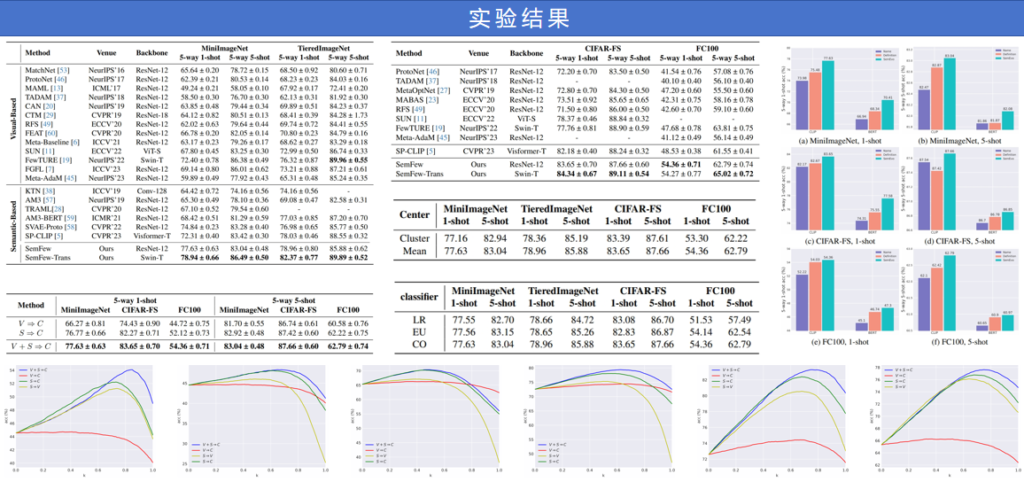
在小样本学习的六个基准数据集上均取得了最先进的性能表现,有力证明了在高质量语义信息支持下,即使基础网络结构也能获得卓越的表现效果。
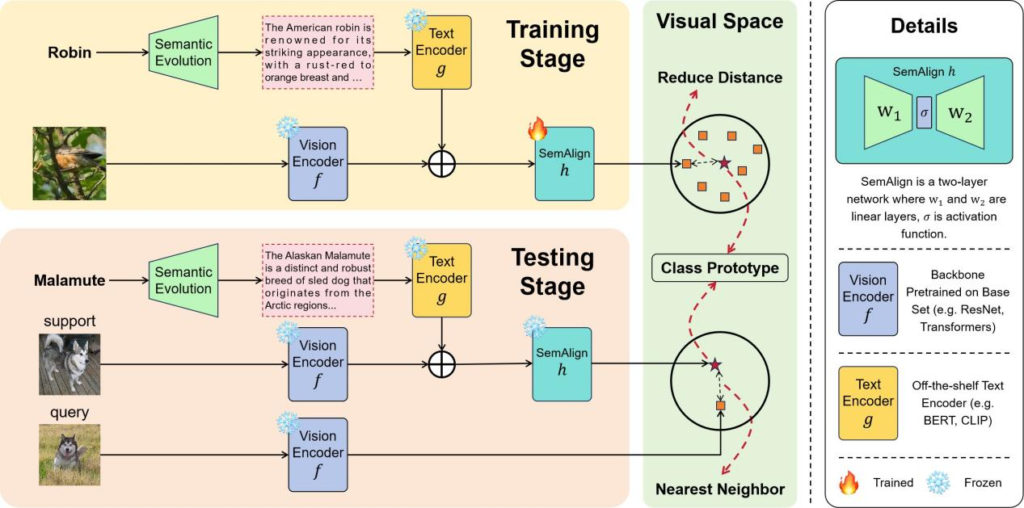
实验结论:本研究在4个广泛采用的小样本学习基准数据集以及2个具有代表性的跨域小样本学习数据集上进行了实验。实验结果显示,本文提出的算法性能优于此前所有的方法,这充分证明了在小样本分类任务中,一个结构简单的网络配合高质量语义能够胜过复杂的多模态模块。
论文地址:https://arxiv.org/abs/2311.18649
代码地址:https://github.com/zhangdoudou123/SemFew
部分作者简介:

张海,四川大学计算机学院2021级硕士研究生,研究方向为小样本学习与多模态学习。

徐浚哲,四川大学计算机学院2020级硕士研究生,研究方向为小样本学习与多模态学习。

贺喆南,四川大学教授,博士生导师,发展规划处副处长。全国学位与研究生教育学会工程专业学位工作委员会委员。研究方向为进化计算、智能优化、智能系统、工业智能。